用户的特殊浏览器
经常有用户使用奇怪的浏览器,来使用我们的产品,然后出问题。
因为产品上的音视频使用了浏览器的 WebRTC 特性,所以对浏览器的要求就很高
当然,从原则上来看,是不应该根据 User-Agent 来提供差异化服务的,应该使用另一种方式:feature detection
可以使用 modernizr 来进行 feature detection
毕竟 WebRTC 是由浏览器 API 组成,通过探测这些 API 是否存在,来判读是否可以使用 WebRTC
但是这个不够严谨,WebRTC 是很新的东西,有些浏览器可以支持,但是支持不够完整和稳定性都有问题。
WebRTC 改变了通信格局; 成为 W3C 和 IETF 官方标准
———— 2021.01.26
所以我们需要去检测用户到底用了什么浏览器,是如何出现了问题的。一个很通用的办法就是检测 User-Agent
从黑曜石浏览器(HEICORE)说起
某年的科大的 CTF 要使用黑曜石浏览器去解题。当然,所谓的黑曜石浏览器是不存在的
不得不说,黑曜石浏览器是我用过最好用的浏览器 用户体验极佳
—— 知乎某用户 如何评价黑曜石浏览器(HEICORE)?
通过设置 User-Agent ,把自己伪装成了黑曜石浏览器
curl http://202.38.95.46:12001/ -H "User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) HEICORE/49.1.2623.213 Safari/537.36"
User-Agent 是什么
用户不能直接去互联网上获取信息,需要一个软件去代表用户的行为,这个软件就是 User-Agent (用户代理)
浏览器就是一种 User-Agent 。用户使用不同的软件去用统一的协议去做相同的事情。
这也是定义在 http 请求里的,每一条 http 请求一定会携带 User-Agent 头
网站的服务者可以通过 User-Agent 头来判断用户使用了什么浏览器,当然也可以根据 User-Agent 的内容来提供差异化的服务
标准语法和历史
原本 User-Agent 浏览器的语法 是很清晰的
User-Agent: <product> / <product-version> <comment>
因为可以根据 User-Agent 的内容来提供差异化的服务,所以当年在浏览器大战时期,浏览器的实现各不相同。
当年 Mozilla (Firefox 的前身)浏览器最强的,很多网站都只对 Mozilla 提供高质量的服务,后来有人把自己伪装成了 Mozilla (没错,就是 IE 先开始的)。
从此 Mozilla/5.0 就变成了 User-Agent 的第一段
后来的浏览就在这上面不断扩充,就像今天这样:
Linux / Firefox
Mozilla/5.0 (X11; Linux x86_64; rv:89.0) Gecko/20100101 Firefox/89.0
Mac OS / Safari
Mozilla/5.0 (Macintosh; Intel Mac OS X 11_3) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1 Safari/605.1.15
Chromium OS / Chrome
Mozilla/5.0 (X11; CrOS x86_64 13904.16.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.25 Safari/537.36
Windows / Edge
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4482.0 Safari/537.36 Edg/92.0.874.0
这就变成了,去识别 User-Agent 变得很困难。目前的识别基本上都是使用正则表达式,配合自己的 User-Agent 库来判断
这方面的库有很多,对比很多后,这个库是比较全的 ua-parser-js
目前几乎所有的网站识别浏览器都是 User-Agent 来判断,目前有两个接口:
前端有浏览器接口:
window.navigator.userAgent
后端可以通过浏览器的 http request header 来拿到 User-Agent
user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36
如何使用 User-Agent
另外,在移动端。因为算力的问题,在有些老旧的处理器上也会出现卡顿的情况
当然,我们可以在浏览器里跑一下 Benchmark 来判断算力是否够用
不过,移动端的 User-Agent 会携带处理器信息(可以去查数据库来判断)
综上,目前所进行的操作是:检测用户浏览器,给予提示,并在文档页显示支持性列表
最后,要通过定义的规则生成这样一个表格
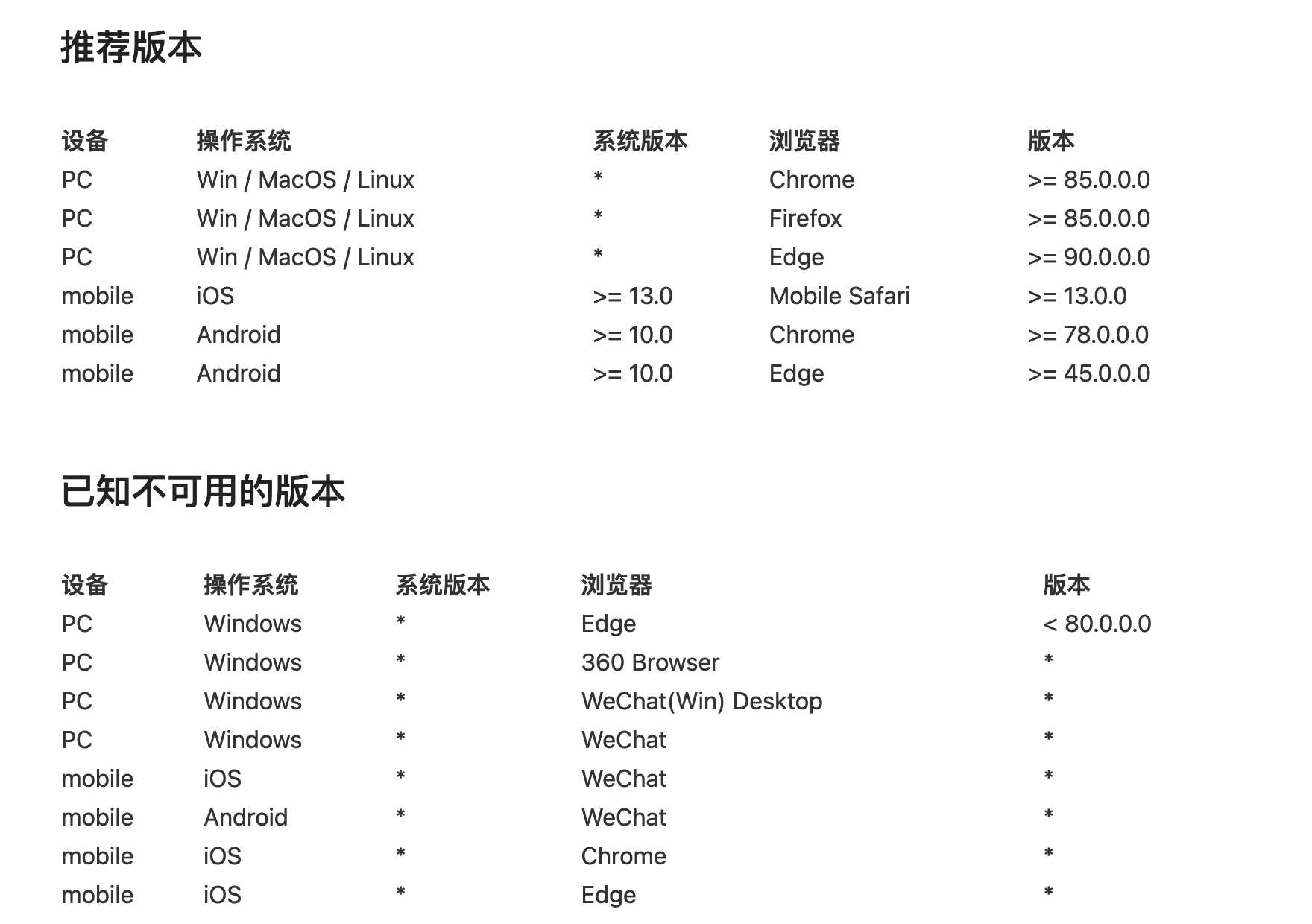
为了降低未来的维护成本要使用一套数据源,既可以检测,又可以在文档页生成列表
ua-parser-js 的返回结果的数据结构比较科学,直接复用这一数据结构
interface Result {
ua: string;
browser: {
name: string | undefined;
version: string | undefined;
};
device: {
model: string | undefined;
type: string | undefined;
vendor: string | undefined;
};
engine: {
name: string | undefined;
version: string | undefined;
};
os: {
name: string | undefined;
version: string | undefined;
};
cpu: {
architecture: string | undefined;
};
}
这样我们可以定义三条规则:
daily_list(某个测试版的浏览器)white_list(测试过没有问题的浏览器)black_list(已知有问题的浏览器)
// 存在优先级关系: daily_list > white_list > black_list
//
// https://www.npmjs.com/package/ua-parser-js
// @params: ua-parser-js.result
// @params: { <list_name>: <whiteList | blackList>}
// @return: string(list_name)
function browserDetect(ua, list) {
const { daily_list, white_list, black_list } = list
if (checkList(ua, daily_list)) return 'daily_list'
if (checkList(ua, white_list)) return 'white_list'
if (checkList(ua, black_list)) return 'black_list'
return ''
}
基于这种数据结构,加入一种简单的语法。支持版本号判断,加入这个几种符号的支持:>, ≥, =, <, ≤
由于没有现成可以用的,所以要自己用 compare-versions 写一段判断,遍历整个结构对比全部的版本号
这样的话配置文件就可以这样写:config/browser.yml
# https://www.npmjs.com/package/ua-parser-js
#
# 本文件的语法是在这个库之上做的修改
# 白名单,完全没有问题的版本
white_list:
- browser:
name: "Chrome"
version: ">= 85.0.0.0"
- browser:
name: "Firefox"
version: ">= 85.0.0.0"
- browser:
name: "Edge"
version: ">= 45.0.0.0"
device:
type: "mobile"
os:
name: "Android"
version: ">= 10.0"
black_list:
# 老版本的 Edge 不支持
- browser:
name: "Edge"
version: "< 80.0.0.0"
os:
name: "Windows"
# 手机微信内置浏览器
- browser:
name: "WeChat"
device:
type: "mobile"
我们的产品的用户上至自己编译浏览器自己用的极客,下至用微信内置浏览器的小白
所以要给使用 beta 版,dev 版,canary 开发版,nightly 版给予提示。这个 WebRTC 不稳定,可能会有问题。
这件事情出现过,有人用了开发版的浏览器,音视频不稳定,然后他又更新了的版本。。。
由于开发版浏览器并不会在 ua 里面携带 dev 的标识。只能通过版本号来判断。可以使用 caniuse-lite 的数据库,取出最新稳定版的的版本号,然后进行版本号比对
但是 caniuse-lite 的数据库有 1.3M 如果直接使用,会打包整个数据库。这个体积的增加了太多
需要优化一下,所以采用把查询结果打包成文件的办法,实际上真正有用的数据非常的少。
创建一个生成器,可以动态创建这个文件 latest_browser_list_generator.js
#!/usr/bin/env node
const browserslist = require('browserslist')
const fs = require('fs')
const list = {
'firefox': true,
'chrome': true,
'edge': true,
}
const latest = browserslist("last 1 version").filter(i => list[i.split(' ')[0]])
fs.writeFileSync('latest_browser_list.js', `export default ${JSON.stringify(latest)}`)
之后定期执行这两个就可以了
npx browserslist@latest --update-dbnode latest_browser_list_generator.js
当然,这个可以用 GitHub action 或 GitLab CI 来每周执行一次
360 浏览器检测
360 浏览器隐藏了自己的 UA 。360 浏览器只有在访问自己的网站(比如:360.cn)是才会在 UA 里携带 QIHU 360SE (360 安全浏览器)或 QIHU 360EE (360 极速浏览器)字段
我们只能使用一下其他的方式,通过一些其他的特征来检测
对待国内浏览器:这个库可以检测到 360
不过这个库的作者并没有提供可以直接使用包。只能把核心代码提取出来
// https://github.com/mumuy/browser/blob/4a50ee18cc76a5013dea3596bb33fbab9ed584c3/Browser.js#L111-L143
if (_window.chrome) {
let chrome_version = u.replace(/^.*Chrome\/([\d]+).*$/, '$1')
if (_window.chrome.adblock2345 || _window.chrome.common2345) {
match['2345Explorer'] = true
} else if (
_mime('type', 'application/360softmgrplugin') ||
_mime('type', 'application/mozilla-npqihooquicklogin')
) {
is360 = true
} else if (chrome_version > 36 && _window.showModalDialog) {
is360 = true
} else if (chrome_version > 45) {
is360 = _mime('type', 'application/vnd.chromium.remoting-viewer')
if (!is360 && chrome_version >= 69) {
is360 = _mime('type', 'application/hwepass2001.installepass2001') || _mime('type', 'application/asx')
}
}
}
// 修正
if (match['Mobile']) {
match['Mobile'] = !(u.indexOf('iPad') > -1)
} else if (is360) {
if (_mime('type', 'application/gameplugin')) {
match['360SE'] = true
} else if (
_navigator &&
typeof _navigator['connection'] !== 'undefined' &&
typeof _navigator['connection']['saveData'] == 'undefined'
) {
match['360SE'] = true
} else {
match['360EE'] = true
}
}
不过这里要注意:navigator.mimeTypes 已经从 Web 标准中移除(也许未来的某天这个方法就没法用了)
判断 360 的版本,是做了一个版本的对应关系
// https://github.com/mumuy/browser/blob/4a50ee18cc76a5013dea3596bb33fbab9ed584c3/Browser.js#L283-L292
function get360SEVersion(u) {
let hash = { '86': '13.0', '78': '12.0', '69': '11.0', '63': '10.0', '55': '9.1', '45': '8.1', '42': '8.0', '31': '7.0', '21': '6.3' }
let chrome_version = u.replace(/^.*Chrome\/([\d]+).*$/, '$1')
return hash[chrome_version] || ''
}
function get360EEVersion(u) {
let hash = { '86': '13.0', '78': '12.0', '69': '11.0', '63': '9.5', '55': '9.0', '50': '8.7', '30': '7.5' }
let chrome_version = u.replace(/^.*Chrome\/([\d]+).*$/, '$1')
return hash[chrome_version] || ''
}
最后
为了网络环境的健康,为了不重蹈浏览器大战时的覆辙。不要针对特定浏览器提供差异化内容。
我们可以告知用户:「我们没有在这个浏览器上充分测试过」
但不能去禁止某个特定的浏览器,或对不同浏览器提供差异化内容
尽可能使用 feature detection 来判读浏览器的支持情况