Linux 4.2后的内核增加了IP_BIND_ADDRESS_NO_PORT 这个socket option来解决这个问题,将src port的选择延后到connect的时候
IP_BIND_ADDRESS_NO_PORT (since Linux 4.2) Inform
the kernel to not reserve an ephemeral port when using bind(2) with a
port number of 0. The port will later be automatically chosen at
connect(2) time, in a way that allows sharing a source port as long as
the 4-tuple is unique.
SO_REUSEADDR Indicates that the rules used in validating
addresses supplied in a bind(2) call should allow reuse of local
addresses. For AF_INET sockets this means that a socket may bind,
except when there is an active listening socket bound to the address.
When the listening socket is bound to INADDR_ANY with a specific port
then it is not possible to bind to this port for any local address.
Argument is an integer boolean flag.
SO_REUSEADDR 还可以重用TIME_WAIT状态的port, 在程序崩溃后之前的TCP连接会进入到TIME_WAIT状态,需要一段时间才能释放,如果立即重启就会抛出Address Already in use的错误导致启动失败。这时候可以通过在调用bind函数之前设置SO_REUSEADDR来解决。
What exactly does SO_REUSEADDR do?
This socket option tells the kernel that even if this port
is busy (in the TIME_WAIT state), go ahead and reuse it anyway. If it
is busy, but with another state, you will still get an address already
in use error. It is useful if your server has been shut down, and then
restarted right away while sockets are still active on its port. You
should be aware that if any unexpected data comes in, it may confuse
your server, but while this is possible, it is not likely.
It has been pointed out that “A socket is a 5 tuple (proto,
local addr, local port, remote addr, remote port). SO_REUSEADDR just
says that you can reuse local addresses. The 5 tuple still must be
unique!” This is true, and this is why it is very unlikely that
unexpected data will ever be seen by your server. The danger is that
such a 5 tuple is still floating around on the net, and while it is
bouncing around, a new connection from the same client, on the same
system, happens to get the same remote port.
By setting SO_REUSEADDR user informs the kernel of an
intention to share the bound port with anyone else, but only if it
doesn’t cause a conflict on the protocol layer. There are at least three
situations when this flag is useful:
Normally after binding to a port and stopping a server it’s
neccesary to wait for a socket to time out before another server can
bind to the same port. With SO_REUSEADDR set it’s possible to rebind immediately, even if the socket is in a TIME_WAIT state.
When one server binds to INADDR_ANY, say 0.0.0.0:1234, it’s impossible to have another server binding to a specific address like 192.168.1.21:1234. With SO_REUSEADDR flag this behaviour is allowed.
When using the bind before connect trick only a single connection
can use a single outgoing source port. With this flag, it’s possible for
many connections to reuse the same source port, given that they connect
to different destination addresses.
SO_REUSEPORT is also useful for eliminating the
try-10-times-to-bind hack in ftpd’s data connection setup routine.
Without SO_REUSEPORT, only one ftpd thread can bind to TCP (lhost,
lport, INADDR_ANY, 0) in preparation for connecting back to the client.
Under conditions of heavy load, there are more threads colliding here
than the try-10-times hack can accomodate. With SO_REUSEPORT, things
work nicely and the hack becomes unnecessary.
(a) on Linux SO_REUSEPORT is meant to be used purely
for load balancing multiple incoming UDP packets or incoming TCP
connection requests across multiple sockets belonging to the same app.
ie. it’s a work around for machines with a lot of cpus, handling heavy
load, where a single listening socket becomes a bottleneck because of
cross-thread contention on the in-kernel socket lock (and state).
(b) set IP_BIND_ADDRESS_NO_PORT socket option for tcp sockets before binding to a specific source ip with port 0 if you’re going to use the socket for connect() rather then listen() this allows the kernel to delay allocating the source port until connect() time at which point it is much cheaper
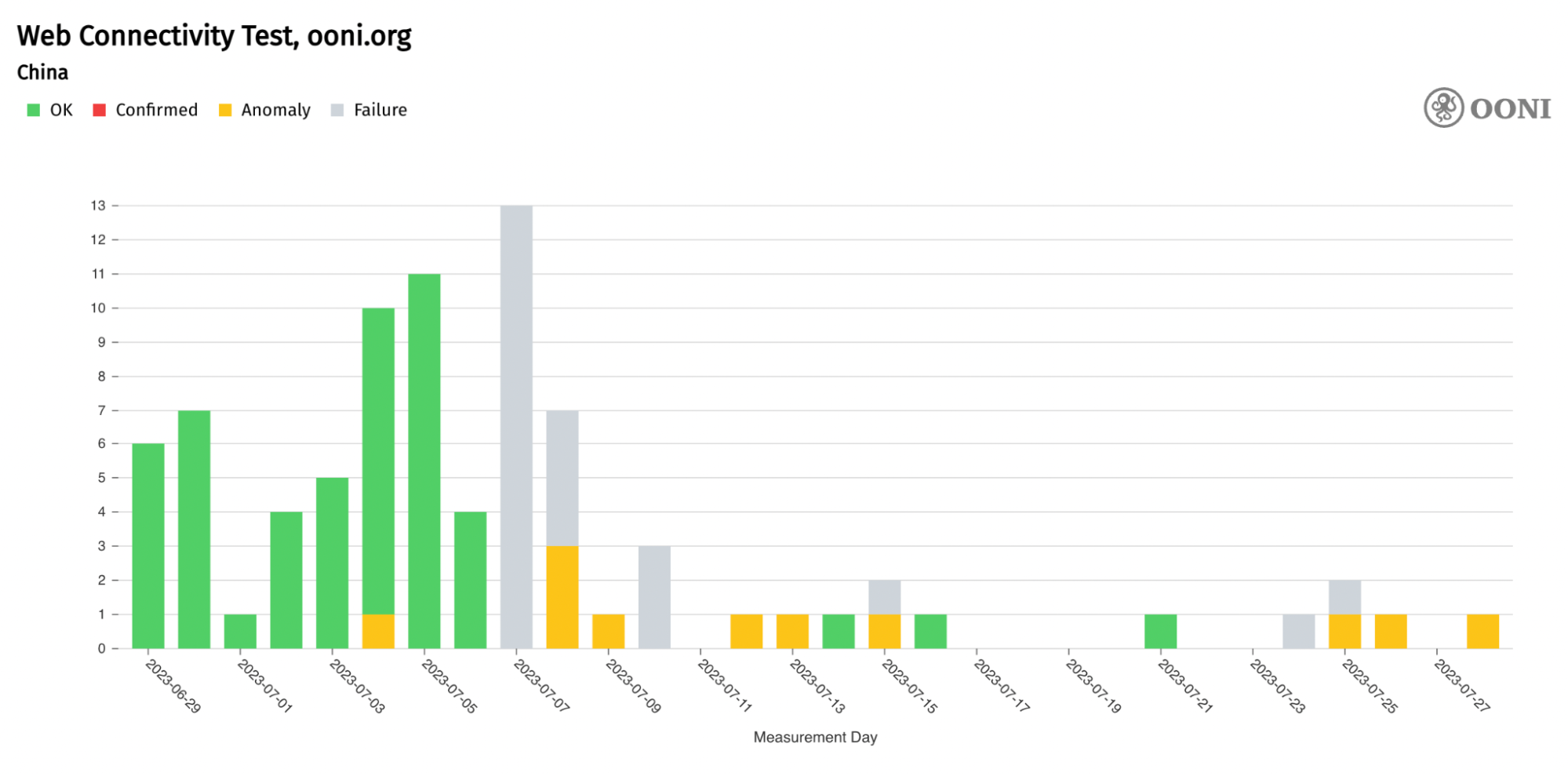
Ephemeral Port Range就是我们前面所说的Port Range(/proc/sys/net/ipv4/ip_local_port_range)
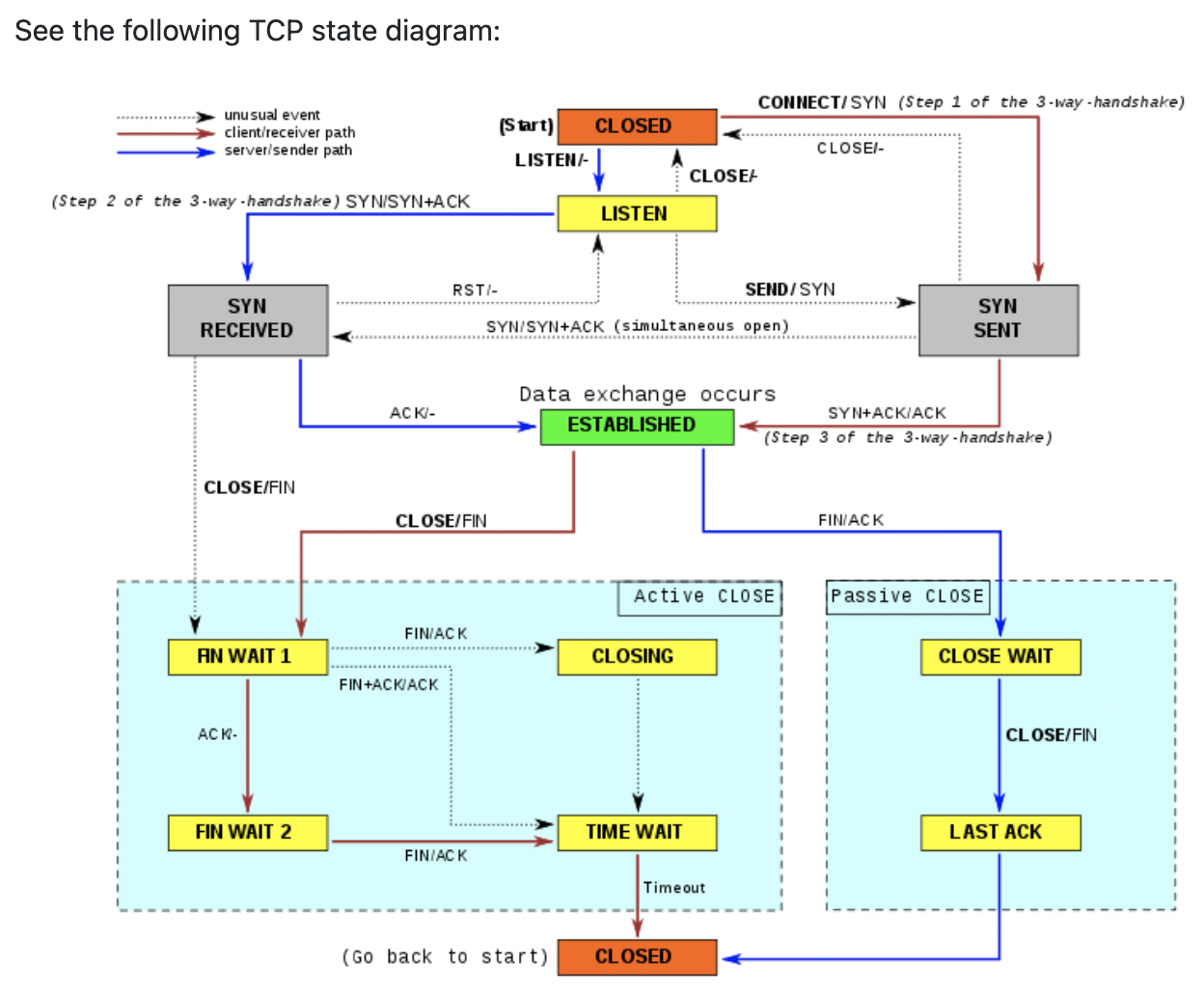
A TCP/IPv4 connection consists of two endpoints, and each
endpoint consists of an IP address and a port number. Therefore, when a
client user connects to a server computer, an established connection can
be thought of as the 4-tuple of (server IP, server port, client IP,
client port).
Usually three of the four are readily known – client machine
uses its own IP address and when connecting to a remote service, the
server machine’s IP address and service port number are required.
What is not immediately evident is that when a connection is
established that the client side of the connection uses a port number.
Unless a client program explicitly requests a specific port number, the
port number used is an ephemeral port number.
Ephemeral ports are temporary ports assigned by a machine’s
IP stack, and are assigned from a designated range of ports for this
purpose. When the connection terminates, the ephemeral port is available
for reuse, although most IP stacks won’t reuse that port number until
the entire pool of ephemeral ports have been used.
So, if the client program reconnects, it will be assigned a different ephemeral port number for its side of the new connection.
linux 如何选择Ephemeral Port
有资料说是随机从Port Range选择port,有的说是顺序选择,那么实际验证一下。
如下测试代码:
#include <stdio.h> //printf
#include <stdlib.h> //atoi
#include <unistd.h> //close
#include <arpa/inet.h> //ntohs
#include <sys/socket.h> //connect, socket
void sample() {
//Create socket
int sockfd;
if (sockfd = socket(AF_INET, SOCK_STREAM, 0), –1 == sockfd) {
perror(“socket”);
//Connect to remote. This does NOT actually send a packet.
const struct sockaddr_in raddr = {
.sin_family = AF_INET,
.sin_port = htons(8080), //arbitrary remote port
tcp_max_tw_buckets — INTEGER Maximal number of
timewait sockets held by system simultaneously.If this number is
exceeded time-wait socket is immediately destroyed and warning is
printed. This limit exists only to prevent simple DoS attacks, you must
not lower the limit artificially, but rather increase it (probably,
after increasing installed memory), if network conditions require more
than default value.
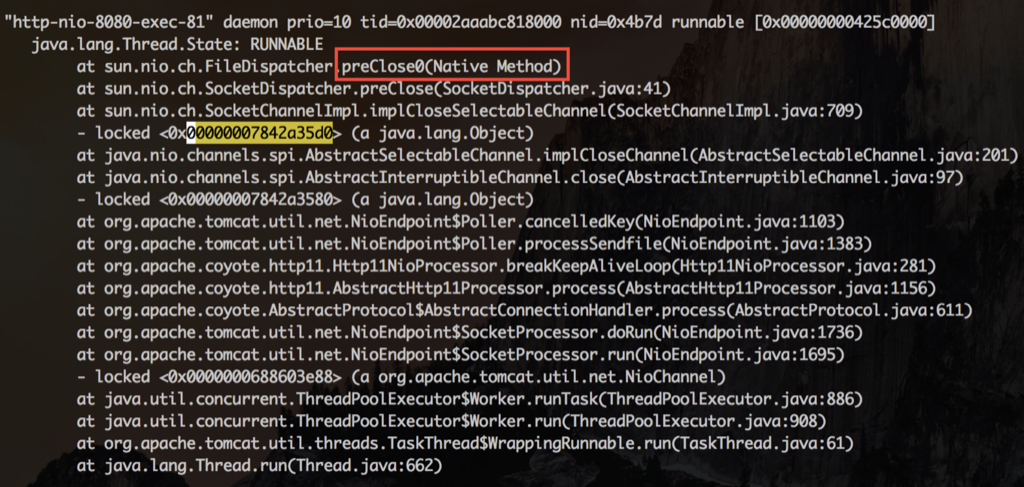
This option specifies how the close function operates for a connection-oriented protocol (for TCP, but not for UDP). By default, close
returns immediately, but ==if there is any data still remaining in the
socket send buffer, the system will try to deliver the data to the
peer==.
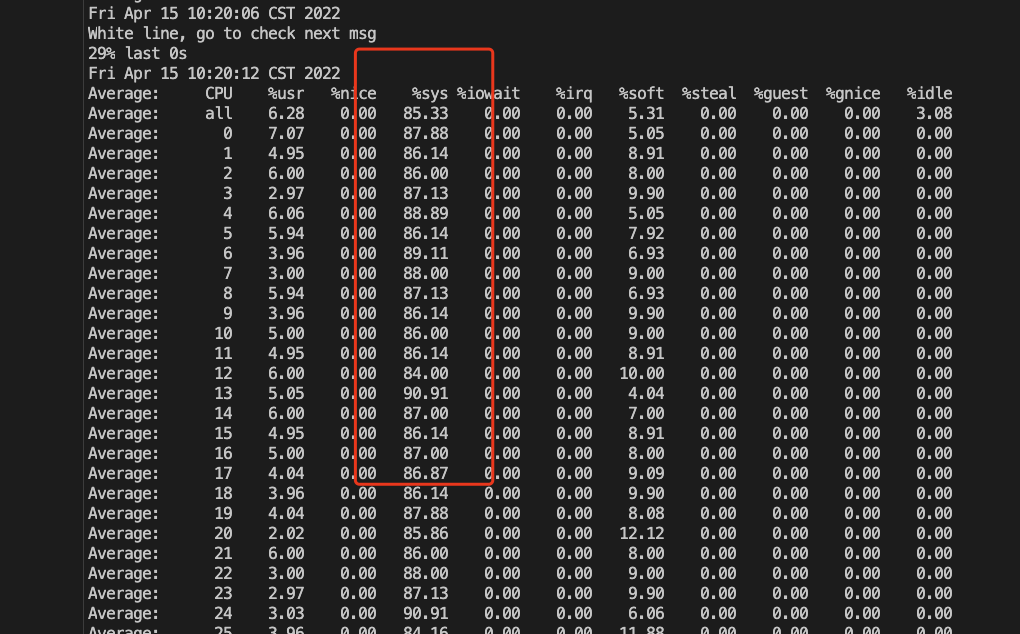
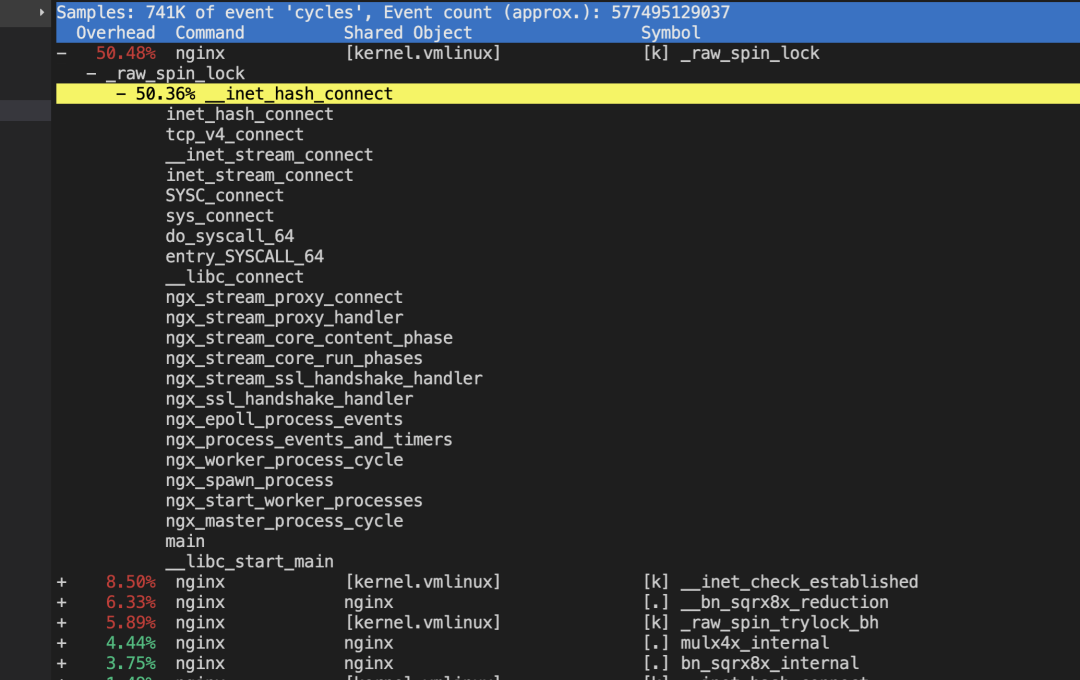
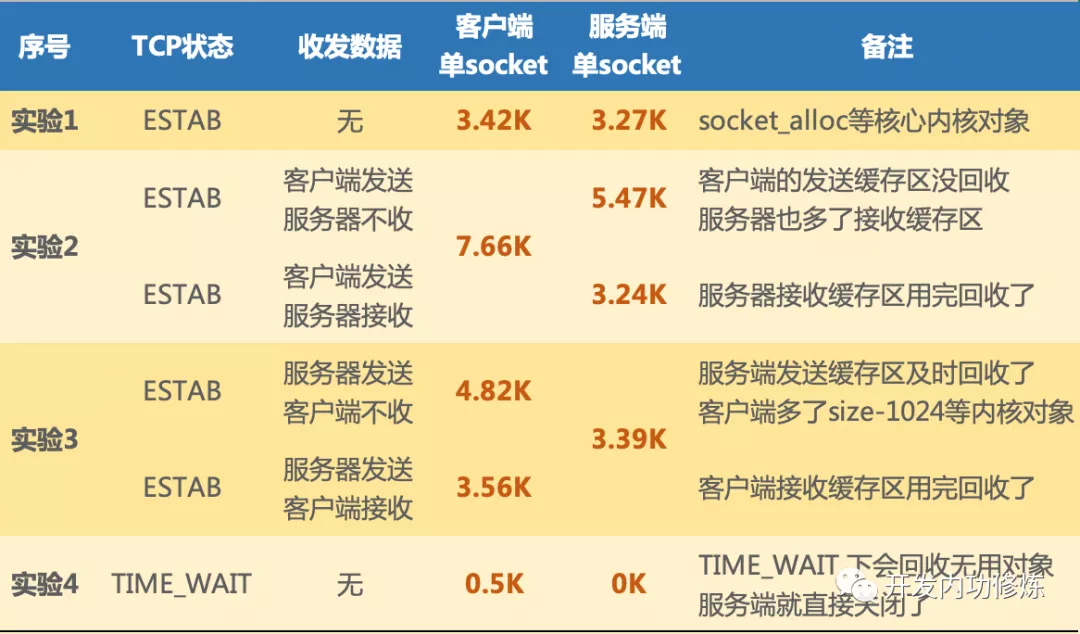
A进程选择某个端口,并设置了 reuseaddr
opt(表示其它进程还能继续用这个端口),这时B进程选了这个端口,并且bind了,B进程用完后把这个bind的端口释放了,但是如果 A
进程一直不释放这个端口对应的连接,那么这个端口会一直在内核中记录被bind用掉了(能bind的端口
是65535个,四元组不重复的连接你理解可以无限多),这样的端口越来越多后,剩下可供 A
进程发起连接的本地随机端口就越来越少了(也就是本来A进程选择端口是按四元组的,但因为前面所说的原因,导致不按四元组了,只按端口本身这个一元组来排重),这时会造成新建连接的时候这个四元组高概率重复,一般这个时候对端大概率还在
time_wait 状态,会忽略掉握手 syn 包并回复 ack ,进而造成建连接卡顿的现象
结论
在内存、文件句柄足够的话一台服务器上可以创建的TCP连接数量是没有限制的
SO_REUSEADDR 主要用于快速重用 TIME_WAIT状态的TCP端口,避免服务重启就会抛出Address Already in use的错误
它可以与DNS over HTTPS(DoH)和DNS over TLS(DoT)解析器一起使用,这使得网络观察者更难以判断是否使用了隧道。 它嵌入了一个适当的可靠性和会话协议(KCP+smux)。客户端和服务器可以同时发送和接收数据,客户端无需等待一个查询接收到响应后再发送下一个查询。同时进行多个查询有助于提高性能。(这就是Turbo Tunnel的概念。) 它使用Noise协议对隧道进行端到端的加密和认证,与DoH/DoT加密分开。
我没有进行任何系统性能测试,但我对Google、Cloudflare和Quad9解析器进行了一些初步测试。使用Google和Cloudflare时,通过Ncat传输文件时,我可以获得超过100 KB/s的下载速度。Cloudflare的DoH解析器偶尔会发送“400 Bad Request”响应(当隧道客户端看到这样的意外状态码时,它会自动限制自身的速度)。Quad9解析器的性能似乎明显不如其他解析器,但我不知道原因。